

AI : “Artificial intelligence is the intelligence of machines and the branch of computer science that aims to create it.”
– Definition from Wikipedia
Having a robot or virtual agent (an example of a virtual agent could be characters in a video game) navigate a space or obstacle course can be a difficult task to plan out (I am going to refer to robots / virtual agents as agents for the remainder of the article). In the case that the environment is unchanging and there are no other agents that can act as obstacles intelligent methods of navigation are not necessary. Assuming that the environment is not going to change all that has to be given to the navigating agent is instructions of how to get from where they are to where they should go. Depending on how space is being conceptualized in their environment and how the agent is capable of moving straightforward instructions such as “Go forward ‘a’ units, turn left ‘b’ degrees, then go forward ‘c’ units, ect” are enough to accomplish the movement. An agent can travel from the beginning to the end of a maze like this assuming the maze environment does not change and the agent’s beginning position does not change.
In the cases where the starting and / or ending positions are unknown but the environment is unchanging some amount of intelligence is required. In order for the agent to navigate the space the agent requires an understanding of a coordinate system that describes the space. An example coordinate system could be the Cartesian Coordinate System which most people are familiar with from geometry or algebra classes. In a two dimensional cartesian coordinate system every point is described as a ‘x’,’y’ coordinate and in a three dimensional cartesian coordinate system a ‘z’ coordinate is included. The agent also requires some amount of memory to store its location on this coordinate system as well as its target position and the locations of obstacles. In the case of a robot the obstacles are stored as they are discovered by some kind of input (examples could be a camera, sonar, lazer, ect) unless the programmer already included the environment in the robot’s memory. However, even if the environment is stored in memory some kind of input for orientation within the space is still necessary. In the case of a virtual agent whether or not they understand the locations of the obstacles in the environment is up to the programmer based on what they want the virtual agent’s behavior to be. If the programmer wants the virtual agent to get from point ‘a’ to ‘b’ as quickly as possible it would be ideal to have the environment stored in the virtual agent’s memory. If instead the programmer wants the virtual agent to wander a space as if it were figuring out where to go the the environment would be stored as the virtual agent “discovered” obstacles.
In this section I am going to assume the agent understands the locations of the obstacles and its orientation within the space. The next task is finding a path to get from the beginning position to the ending position. One method is using Dijkstra’s algorithm which treats the space as a series of nodes that can be traversed. In relation to the cartesian coordinate system the ‘x’,’y’ (and ‘z’ if three dimensional) points would be converted into some kind of unit metric relative to the size of the agent which will act as the nodes for the algorithm. The reason this is done is because the units of a cartesian coordinate system are infinitesimally small which is not useful for the algorithm. When this process is complete the coordinate system can conceptually be thought of instead as a grid made up of cells. One of the cells contains the agent, one cell has the ending position, some number of cells are obstacles cells which cannot be traversed, and the remaining cells are empty cells which can be traversed. Once the grid set up is complete then Dijkstra’s algorithm is run.
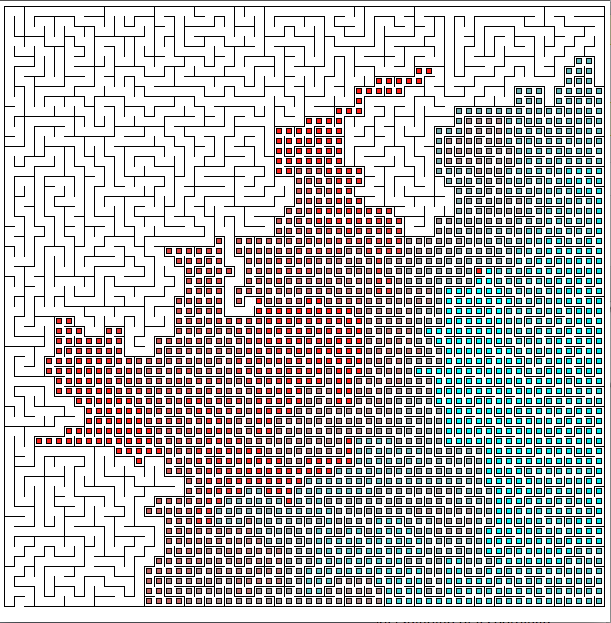
Dijkstra’s algorithm works by traveling to every traversable neighboring node / cell until it reaches the ending node / cell (see animation below).

The first step can be thought of as dumping water at the agent’s current position and marking where the water has spilled. Each node / cell the water spreads to is then numbered based on how many nodes / cells the water has visited. If the order for numbering was clockwise based on the agent’s position then during the first step the cell above the agent would be node 1, the cell to the right of the agent would be 2, the cell below the agent would be 3, and the cell to the left of the agent would be 4. During the second step the cell two units above would be numbered 5, the cell one unit above and one right would be 6, the cell two units right would be 7, ect. However, if one of the cells to be numbered contained an obstacle then it would not be numbered and also would be considered not traversed. The numbering by water spilling method would continue until the cell that is the ending position was numbered. Once the ending cell is reached the path to get from the starting position to the ending position is found by backtracking from the ending position. Instructions for the agent to follow would be made by starting at the ending position and traveling one cell at a time always going to the cell that has a lower marker number from the water spilling step. This process will always end at the agent’s current position and then the agent can take the instructions generated from the backtracking and reverse them to get to the ending position (they are reversed because they began from the ending and ended at the beginning).
In the cases where the environment is stored in memory but the environment changes over time, or there are other agents who can move in the way of the ending position this algorithm can still be used. The only difference is that the solution to get to the ending cell must be found every time the agent moves, the environment changes, or another agent moves. Other agents would be treated as obstacles during the water spilling step and the information about which cells contained obstacles and which were traversable would have to be updated whenever a change occurred. It is worth noting that although this method will accomplish the task of reaching the ending position (if it is possible) it has two problems:
- If the exit cannot be reached (the obstacles do not allow it) the algorithm will crash the program because it will attempt the water spilling method forever. This can be avoided by having an “escape” method in the algorithm such as specifying that after some number of steps that if the ending position has not been reached to stop trying (for example if after 1000 steps of water spilling if the ending position has not been reached then stop trying).
- This method of reaching the ending position is not a realistic way of moving through an obstacle course because it assumes the agent has a perfect understanding of the environment. The routes the agent will take are the shortest distance possible so if the behavior of wandering is desired then “imperfections” must be included to the instructions.
To see a visualization of an agent making use of the water spilling method in a maze click here.
To see a virtual agent making use of the algorithm mentioned in the article click here.
Article Written by: Alex Simes